Cognitive Health
Brain Compass
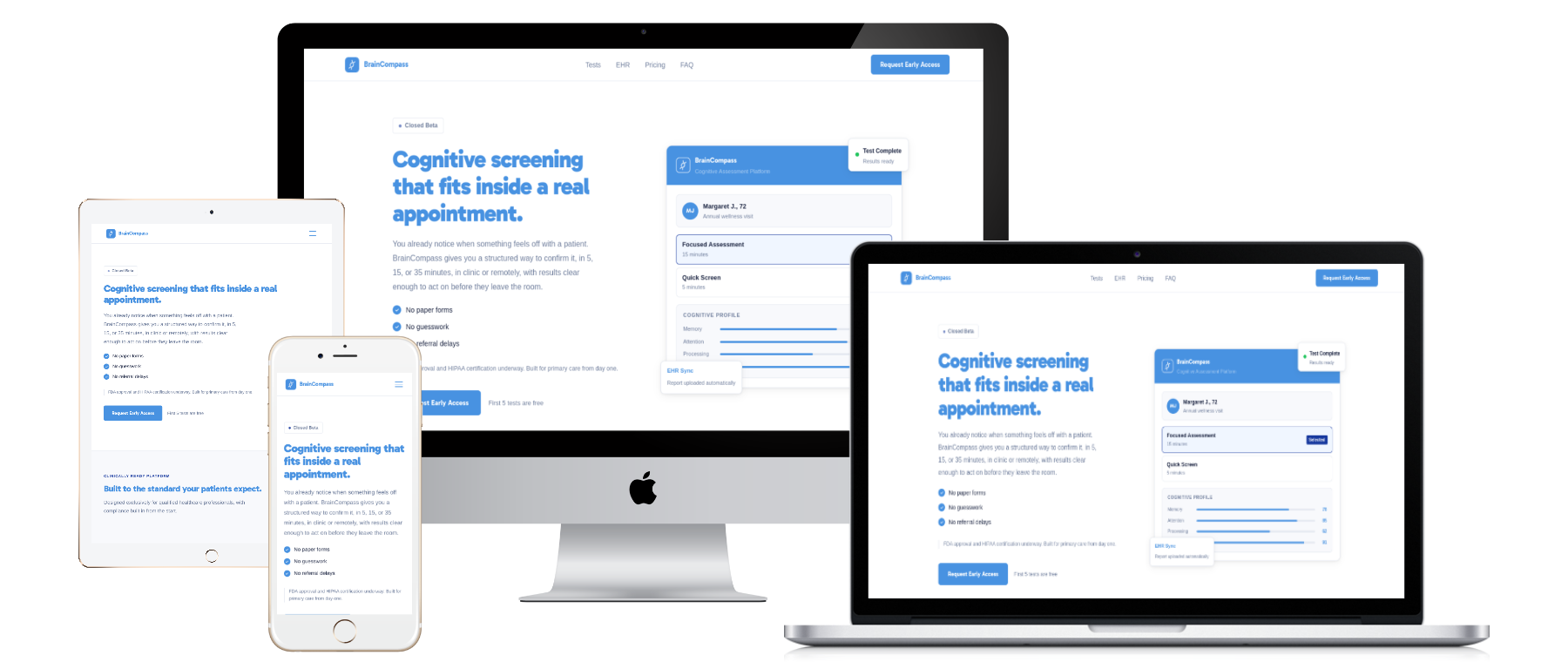
Turning paper tests into clinical intelligence
Key Results
Measured outcomes that matter
- Designed for elderly patients (hands-free, voice-guided flows)
- Deterministic + AI grading for consistent, explainable results
- AI-assisted analysis powered by Anthropic's Claude models
- Modular test architecture that adapts as clinical research evolves
- HIPAA compliant by design
Starting Point
Where the workflow broke
Paper assessments were inconsistent, slow to score, and nearly impossible for elderly patients to complete independently. The workflow needed to be clearer, faster, and easier to run—without losing clinical defensibility.
End-to-end Ownership
Built through the full delivery loop
Initial Consulting
Shaped the product vision around the real clinical workflow: what clinicians need, what patients can do without assistance, and what “done” looks like in trials.
Product Research
Mapped assessment UX for elderly users, clinical pacing, and where friction caused incomplete tests—then grounded every decision in real behavior.
Product Roadmap
Built a phased roadmap that prioritised clinical utility first—then iterated toward scale without breaking the core workflow.
Tech Selection and Infrastructure
Chose a durable, modular architecture so new assessments can be added without rework. Set up the foundations for CI/CD and reliable delivery.
Team Assembly
Assembled engineering, AI, and QA around one clear line of ownership to ship the full end-to-end system.
UI and UX Design
Designed every screen for “90-year-old mode”: clarity over cleverness, with voice narration and hands-free navigation to prevent drop-off.
Branding and Identity
Created a visual language that fits clinical trust—so the product feels native to healthcare, not like a consumer app.
Full Stack Development
Built across web and mobile, backed by microservices and an AI grading pipeline using Anthropic's Claude models. Delivered voice narration, remote sharing, and consistent scoring.
User Interviews and Testing
Validated the workflow with clinical users and elderly patients, iterating until the system performed reliably in real conditions.
Deployment and Closed Beta
Managed deployment into closed beta and supported the path into FDA clinical trials—ensuring the workflow stays stable as the product evolves.
What Makes It Different
AI-native where it matters
Fully voice-narrated & guided
A hands-free workflow that prevents “stuck” moments and enables independent completion—designed for elderly users.
Modular test architecture
New cognitive assessments can be added without touching existing code paths, keeping clinical research moving.
Deterministic + AI grading
A custom pipeline combines rule-based logic with Anthropic's Claude models to produce consistent, explainable outputs for clinicians.
Remote test sharing
Tests can be started and completed remotely, enabling flexibility beyond the clinic room.
HIPAA compliant by design
Security and compliance were built into the system from the start—not bolted on after the fact.
Our Process
Workflow-first. AI-native delivery.
Workflow discovery
We start by mapping the exact patient + clinician workflow, then define “success” as measurable outcomes, not just a roadmap.
AI workflow design
We define where Anthropic's Claude models help, where deterministic rules are required, and how results remain explainable for clinical review.
UX for real users
We design for the hardest users first—so the system stays usable in the real world, not just demos.
Clinical validation
We test with real clinicians and patients, then iterate until the workflow holds up under pressure.
Deployment to trials
We ship in phases, validate reliability, and support the product as it moves into trial environments.
“Upkram took our idea and turned it into a fully working, voice-guided cognitive screening workflow. The system is clear for patients, and consistent for doctors who need defensible results.”